
Come evitare una coda sul nostro percorso ? Dove andare a mangiare un pesce fresco stasera? Ci risponde l’app dello Smartphone! Nella vita quotidiana come in azienda, siamo da sempre convinti che dobbiamo essere guidati dai dati. E oggi l’informazione giusta si trova in mezzo a una massa sempre crescente di dati… Dati che possono essere già presenti sui sistemi dell’azienda (ERP, gestionale, …), oppure dati pubblici messi a disposizione, si parla di Open Data. Ma come navigare i dati Open Data in modo dinamico e chiaro per sfruttarli al massimo?
eXcelent, società specialista di gestione della performance aziendale, e Marco Pozzan, esperto di Business Intelligence, hanno unito le forze per proporre un percorso consentendo di costruire facilemente un modello di analisi di dati Open Data molto voluminosi in Power BI
Costruire un datamart semplice sulla base di numerosi file con la suite Power BI di Microsoft
Raramente i dati Open Data sono presenti sotto la forma di database a cui collegarsi. Spesso volentieri sono costituiti da file (JSON, XML, CSV…). In questo articolo vi spieghiamo com’è possibile creare un datamart sulla base di numerosi file, senza dover alimentare un database vero e proprio. Questo è diventato possibile grazie a tutta la suite Power BI rilasciata dalla Microsoft in questi anni.
Oggi si parla di Self Service BI: effettivamente, tutti i dati sono disponibili (“Open”) e gli strumenti sono addirittura gratuiti (la PowerBI desktop è free, si paga solo quando si condividono dati con altri), o di un costo molto contenuto, come ve lo illustreremo più avanti. Se ormai degli strumenti molto potenti sono disponibili per tutti gli utenti, servono anche competenze specifiche. Quindi noi preferiamo parlare di Self Service BI “guidata”: con una assistenza mirata sui punti più complessi, un utente correttamente formato è in grado di sviluppare un proprio modello. Perché non tutti abbiamo bisogno della stessa informazione.
Fare benchmarking sui dati di bilancio Open Data
In eXcelent ci occupiamo di Corporate Performance Management; tradizionalmente il bilancio rappresenta la performance economica-finanziaria dell’azienda. Qualche anno fa, abbiamo sviluppato una App in Power BI per navigare i dati dell’XBRL di una o più società…
Ma analizzare i propri dati non basta : serve anche studiare la concorrenza. Per poter analizzare i competitors bisognerebbe scaricare tutti i bilanci di tutte le aziende di un determinato settore. Possibile? In Italia, dovremmo scaricare bilancio per bilancio, con un costo non indifferente (ogni bilancio costa qualche euro) e navigarli ad esempio con la nostra app Power BI… Quindi la massa di dati è comunque limitata.
In Francia, invece, dalla fine del 2017 i bilanci delle aziende francesi sono Open Data (per i bilanci non protetti da privacy): significa che tutte le informazioni finanziarie depositate ogni anno dalle società francesi sono disponibili (quello che è l’XBRL in Italia), sotto la forma di migliaia di file zip trasmessi ogni giorno dall’ente pubblicato incaricato.
Power Query : per trasformare migliaia di file xml
Il primo problema è il formato dei dati: una volta unzippati sono dei file XML (un file per ogni deposito). Per aggregare e trasformare quei file usiamo Power Query che è un tool fondamentale di Power BI : si collega alle fonti (database o file), pulisce e prepara i dati in un formato tabellare. Power Query riesce a leggere bene i file XML, è una funzionalità importante (legge anche file JSON, .CSV…) Un’altra funzionalità molto interessante di Power Query è che riesce a leggere tutti i file (che hanno un tracciato identico ovviamente) all’interno della stessa cartella. Questa funzionalità ci è molto utile visto che abbiamo da gestire migliaia di file ogni giorno. Cosi’ ci aggrega tanti dati da solo.
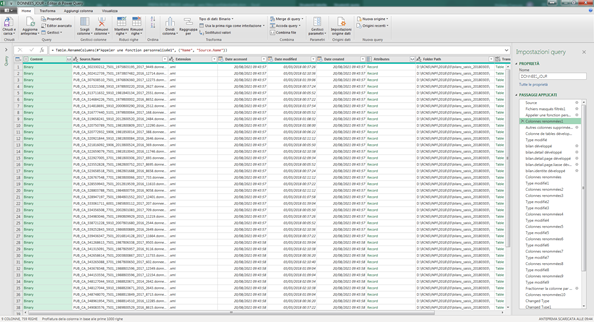
Inizialmente abbiamo sperato di poter navigare quei file con la Power Query e caricarli all’interno del nostro modello Power BI: ma navigare direttamente le migliaia di XML significava aspettare troppo tempo prima che caricasse…
Nel nostro caso sfruttiamo la PowerQuery per fare un merge di tutti i file passati dall’Open Data : dai 5.000 file trasmessi ogni giorno (mediamente), ci creiamo un file unico per ogni giorno (in formato .csv), con all’interno tutte le righe trasmesse per tutti i bilanci depositati ogni giorno. Effettivamente è un altro passaggio importante che ci ha fatto fare l’ETL di Microsoft; ma navigare i file .csv andava bene finché i giorni erano pochi…(fino a un mese di depositi, diciamo). Mediamente sono 700mo di dati ogni mese, in un anno 8 giga di dati… A questo punto neanche leggere i file .csv era sufficente : avevamo bisogno di ambiente più performante….
Synapse : creare un database SQL Server a partire da file csv
Dove posizionare questi dati sapendo che vogliamo evitare di dover creare un datawarehouse? Infatti vogliamo che i nostri modelli rimangano abbastanza semplici senza dove coinvolgere in maniera pesante il reparto IT dell’azienda.
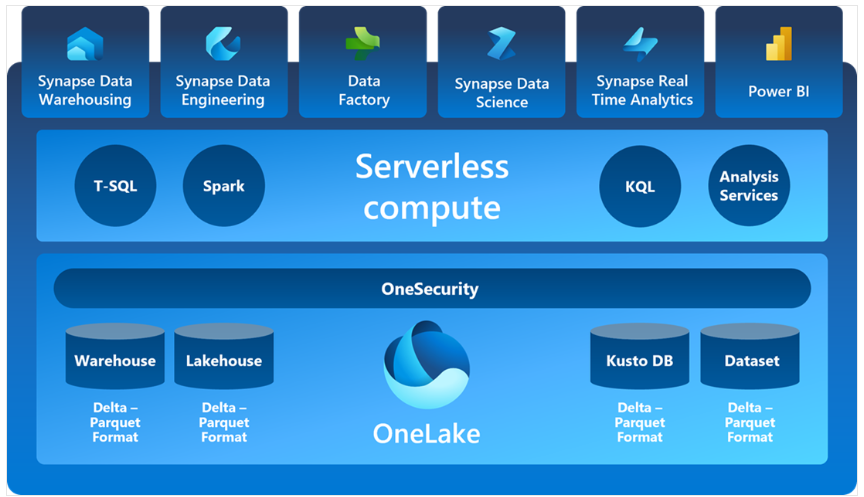
Synapse : che cosa è ?
Lo strumento che fa per noi è Synapse : è una componente del Cloud Microsoft che la definisce cosi : “Azure Synapse Analytics è un servizio di analisi senza limiti che riunisce integrazione dei dati, funzionalità aziendali di data warehousing e analisi dei Big Data. Offre la libertà di eseguire query sui dati in base alle tue esigenze, usando risorse serverless o dedicate, su larga scala. Azure Synapse combina questi mondi grazie a un’esperienza unificata per l’inserimento, l’esplorazione, la preparazione, la gestione e la distribuzione dei dati per esigenze immediate di business intelligence e Machine Learning.”
Un altro vantaggio importante di Synapse è cje ha un costo puramente variabile: si paga solo l’utilizzo che si fa del servizio, che va in base al consumo. Queste tariffe sono particolarmente adatte quando si tratta di navigare i dati Open Data.

Dove risiedono i nostri dati in Synapse ?
Nel nostro caso Synapse ci consente di trasformare semplici file .csv in un database SQL Server. I file sono caricati in un ambiente cloud, poi vengono trattati come se fossero delle tabelle di un database relazionale! Una volta creato lo script di caricamento, basta posizionare i file nella cartella ed avviare gli script per poterli navigare. Come potete vedere, nella sezione “Linked”, troviamo i nostri file “.csv” creati dalla Power Query : un file al giorno, che va da qualche kilobyte al megabyte (40megabyte di csv non è proprio poco!)
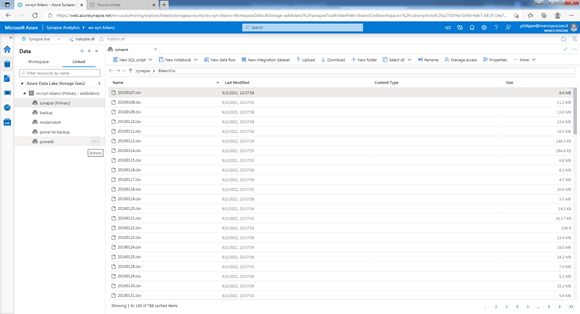
In realtà in Synapse non useremo dei simplici file .csv : quelli saranno trasformati automaticamente in dei file di tipo “parquet” : che hanno un livello di compressione notevole per ridurre la dimensione di quei file; infatti la dimensione dei file determina la velocità del nostro modello Poi ci siamo creati delle viste che indicano al sistema la definizione delle tabelle :
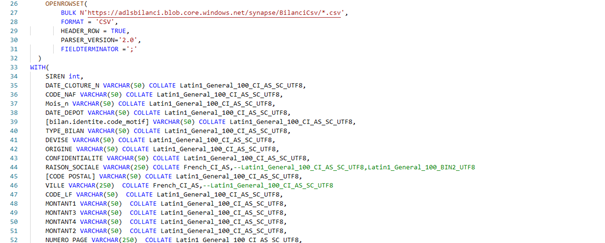
Infine basta creare uno script che carica i dati dai nostri file .csv in una tabella navigabile con più velocità, sfruttando la vista precedentemente creata : Nella sezione Workspace, troviamo gli altri ambienti classici di un SQL server : schemas, security, views… Solo che non troviamo i database, troviamo invece “external resources” e “external tables”.
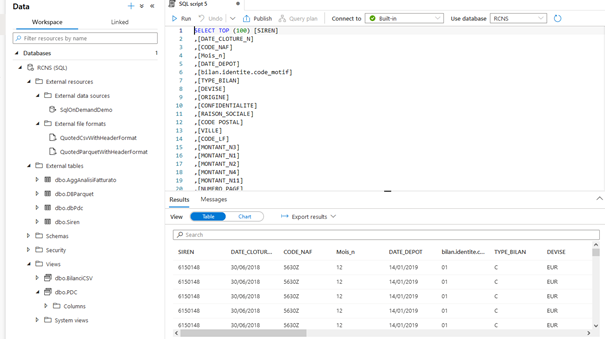
Direct Query : navigare senza scaricare i dati Open Data
Il terzo problema è appunto la massa di dati : per ogni bilancio depositato, ci sono centinaia di voci presenti, dalle voci del conto economico ai dettagli della nota integrativa della società. Una prima possibilità che dà Power BI è la possibilità di usare la modalità “Direct Query”: in questa modalità, i dati non sono più scaricati in memoria quando il modello viene aggiornata. I dati sono recuperati solo quando l’utente effettua una selezione su un visual di Power BI. Questa modalità consente di non dover limitare i dati e di dare all’utente la possibilità di navigare tutta la mole di dati. Ovviamente questa modalità richiede una buona connessione (fibra…) ed è da evitare per le query standard.
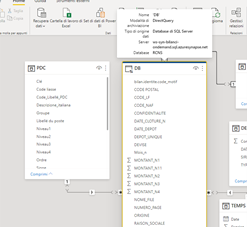
Le aggregazioni : l’importanza di essere preparati
Per consentire di avere tempi di analisi veloci, abbiamo deciso di calcolare delle aggregazioni direttamente in Synapse. Questo significa che abbiamo selezionato degli indicatori che ci sembravano quelli più pertinenti (fatturato, indebitamento finanziario ad esempio) e li abbiamo precalcolati in un tabella sintetica. Per fare quelle aggregazioni, Synapse ci ha consentito di creare delle tabella più sintetica facendo dei raggruppamenti di SQL. E’ una soluzione semplice ma potente, che richiede una conoscenza limitata del linguaggio SQL.
Quella tabella essendo molto più snella, abbiamo potuto scaricarla nel modello Power BI.
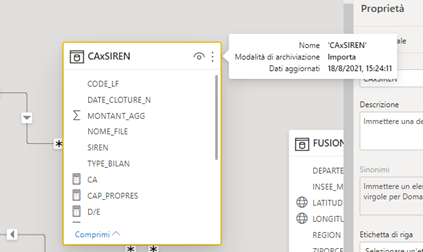
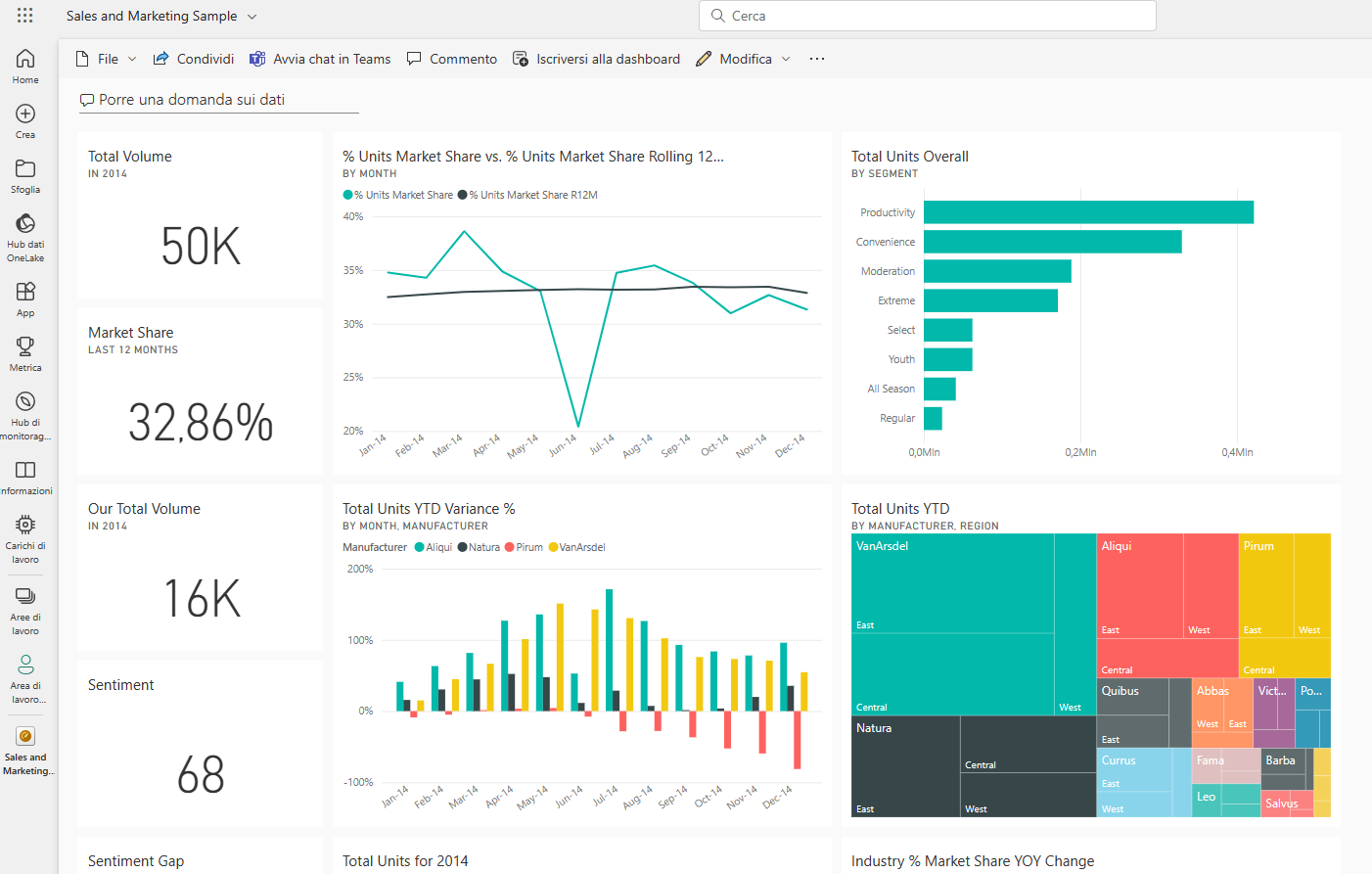
La navigazione di dati Open Data : milioni di bilanci depositati
In un solo modello di dimensioni ridotte (230 megabyte), che puo’ sembra grande ma in realtà un file unico di dati in PowerBI non deve superare 1 gigabyte, quindi parliamo di dimensioni gestibili, navighiamo i dati di più di 1 milione di entità, con più di 2 millioni di bilanci! Il tutto su un PC personale!
Per fare benchmarking si possono utilizzare delle tabelle che servono a filtrare per :
- zona geografica;
- settore;
- tipo di bilancio (ordinario, abbreviato, consolidato, bancario, assicurativo)
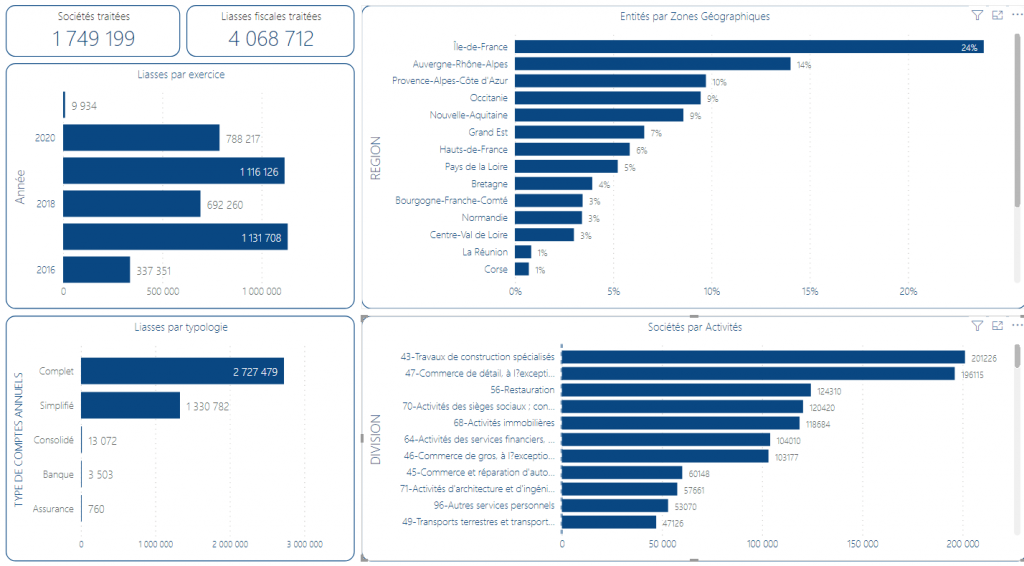
Dal cruscotto iniziale che dà un’overview dell’insieme dei dati gestiti, possiamo passare ad un ambiente di selezione in base a settore / zona geografica / tipo bilancio
Poi eventualmente è possibile selezionare solo una entità per analizzare i propri dati :
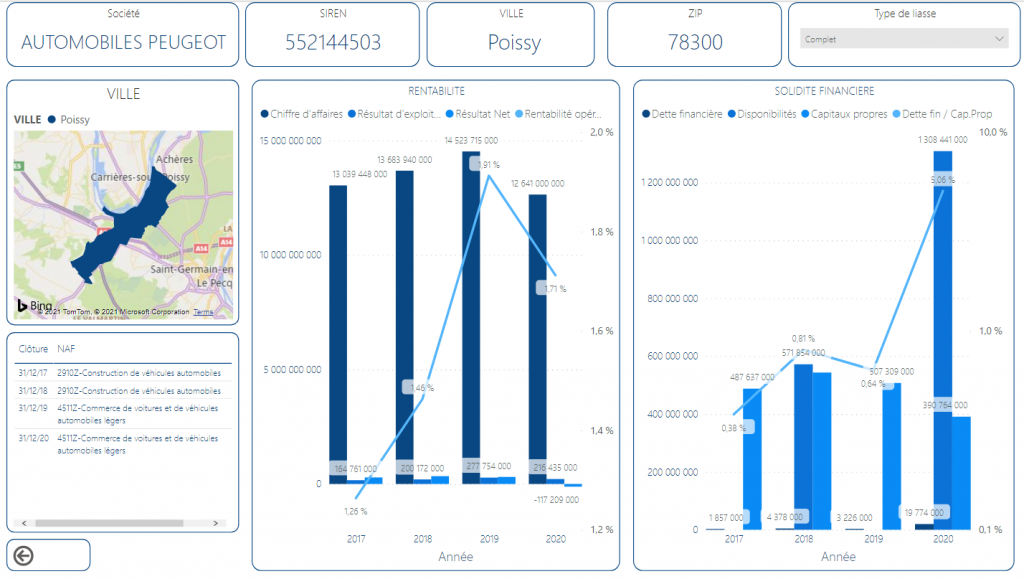
Con l’utilizzo della Power BI associata al servizio Synapse di Microsoft, siamo riusciti a creare un ambiente potente di navigazioni di milioni di bilanci depositati, senza dover ricorrere ad una strutturare compessa. Con questa impostazione, navigare i dati Open Data diventa possibile per tutti gli utenti business formati alla Power BI e guidati dalle persone competenti.
Per approfondimenti :

{kind=link}
{kind=link}
{kind=link}
{kind=link}
Scrivi un commento
You must be logged in to post a comment.